Varnish Data Pipeline Accelerator
Accelerate AI/ML Workflows with High-Performance Data Caching
The Varnish Data Pipeline Accelerator is designed to handle ever-growing data volumes and performance bottlenecks, enabling high-speed, efficient data access that keeps your AI infrastructure operating at peak performance.

Why Choose Varnish Data Pipeline Accelerator?
Varnish Data Pipeline Accelerator seamlessly integrates with leading storage systems like AWS S3, Google Cloud Storage, NAS, and more.
By accelerating data flow between storage and compute clusters, we ensure low-latency, high-throughput access to massive datasets.
This technology transforms how you handle AI/ML workloads, from training complex models to performing real-time analytics.
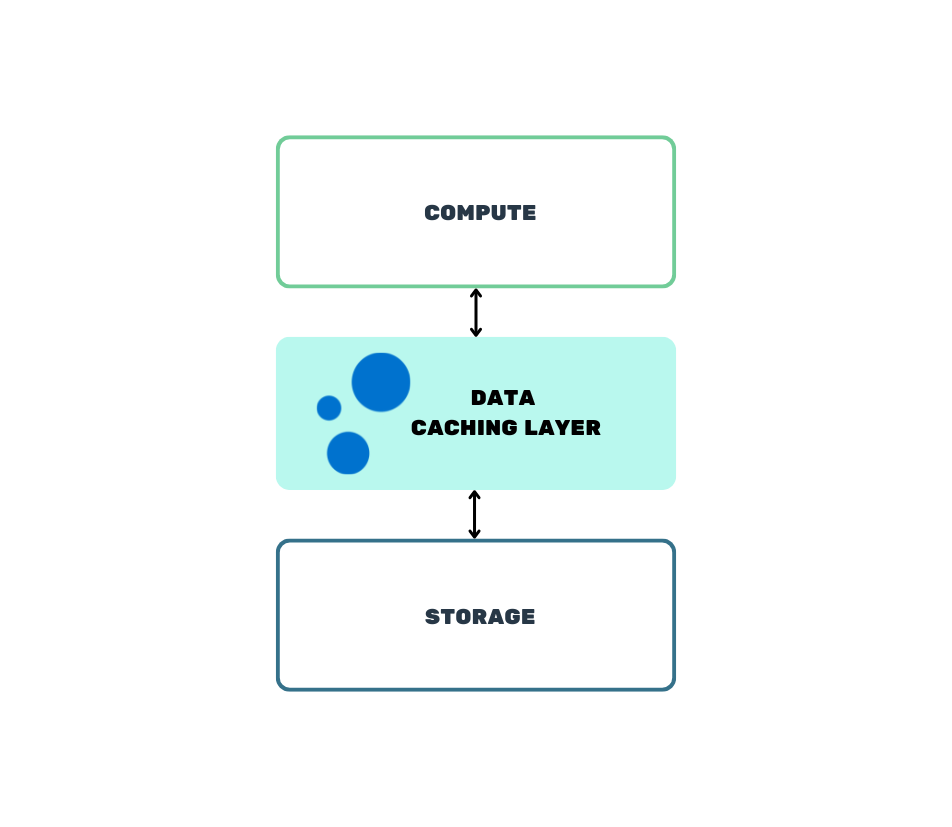
Advantages of Varnish Data Pipeline Accelerator
Maximize GPU Utilization
Keep your GPUs fully occupied with continuous data flow, eliminating costly idle time and maximizing return on investment.
Distributed Data Acceleration
Move high performant access to petabytes of data and billions of files across disparate storage devices and services closer to the GPU compute cluster.
Ultra-Low Latency
Drastically reduce data retrieval times to under 10 milliseconds, facilitating real-time optimizations and immediate decision-making.
High Throughput
Transfer data at speeds of up to 1.5 Tbps per server, supporting the most demanding data-intensive applications with ease.
Lower Infrastructure Costs
Minimize use of expensive high performance on-premises storage and slash cloud egress fees by using a hybrid caching architecture.
How it Works
Acting as a customizable, programmable caching layer, the Varnish Data Pipeline Accelerator optimizes data flow by intelligently prioritizing and pre-fetching frequently accessed data and serving it directly to GPUs and CPUs.
With advanced configuration capabilities and support for edge processing, Varnish ensures compute infrastructure has instant access to critical information—precisely when and where it's needed.
- Persistent High-Speed Cache: Fault-tolerant, highly available cache storage optimized for large AI/ML datasets.
- Slicer Technology: Efficiently handles fragments of large data objects, speeding up loading times for machine learning processes.
- Hybrid Storage Architecture: Combines NVMe for rapid indexing and HDDs for cost-effective data storage, striking a balance between performance and savings.
- Robust Security: Protect data with TLS encryption and unique cryptographic keys, safeguarding information both in transit and at rest.
Who is it for?
Algorithmic Trading / HFT
Accelerate access to real-time and historical data, enabling trading algorithms to execute decisions instantly for maximum market advantage.

Autonomous Vehicle Development
Speed up AI model training with rapid access to sensor data, reducing time-to-market for autonomous navigation technologies.

Scientific Research
Enable faster data processing in areas like genomics, climate modeling, and astronomy, driving research breakthroughs at unprecedented speeds.
How to Deploy
Choose from flexible deployment models to match your infrastructure needs:
- Fully Cloud-Based: Deploy all components in the cloud for unmatched scalability.
- Hybrid: Combine on-premise compute and caching clusters with cloud storage for a balanced approach.
- On-Premise: Keep all components in-house for ultra-low latency and full control over your data environment.

Empower your AI/ML operations today
Ready to transform your data access and unlock the full potential of your compute resources? Contact us today to learn more or to schedule a demo.
